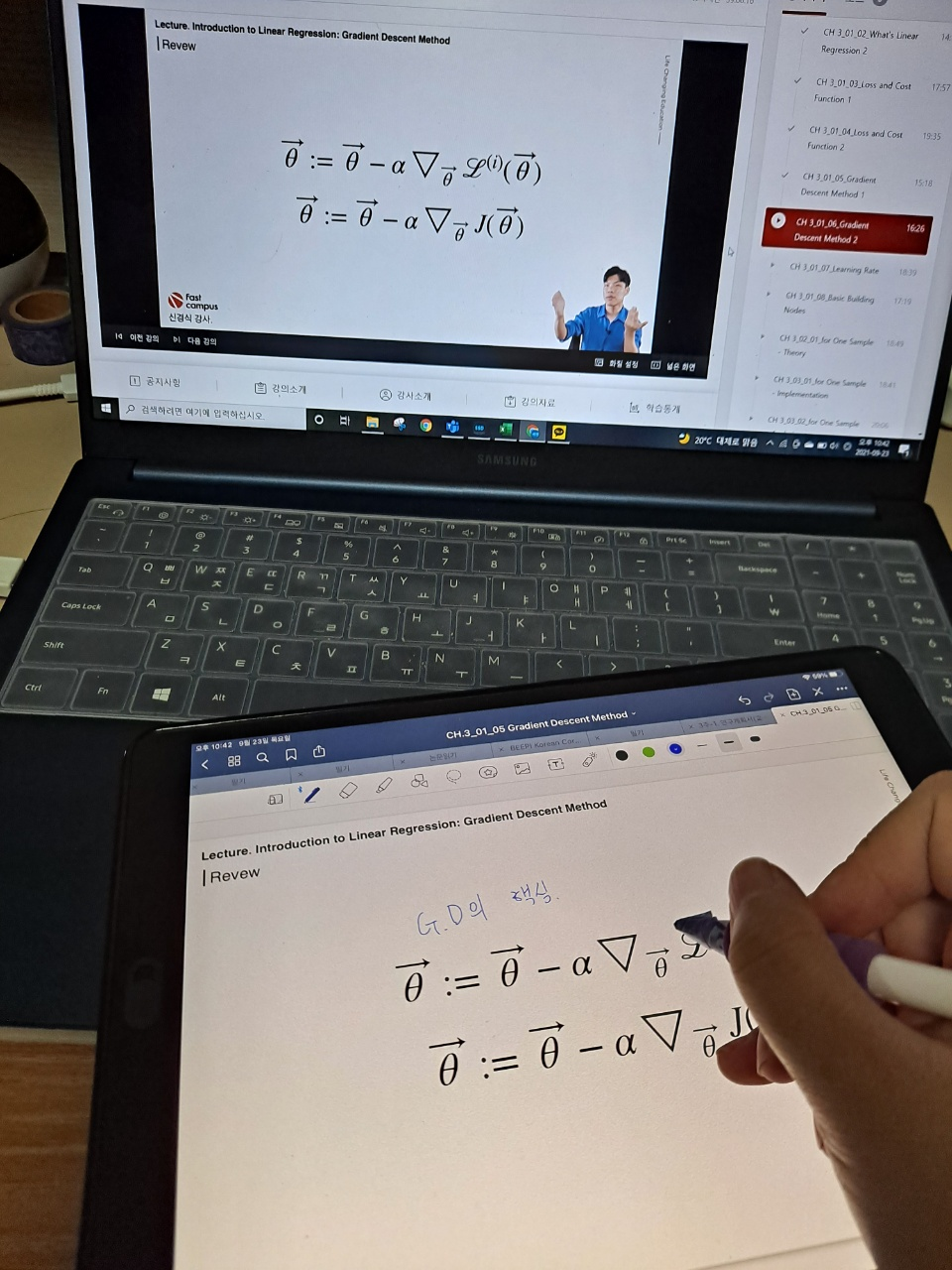
2021. 09. 30 목요일 25일차
3-4-2 for Several Samples - Theory

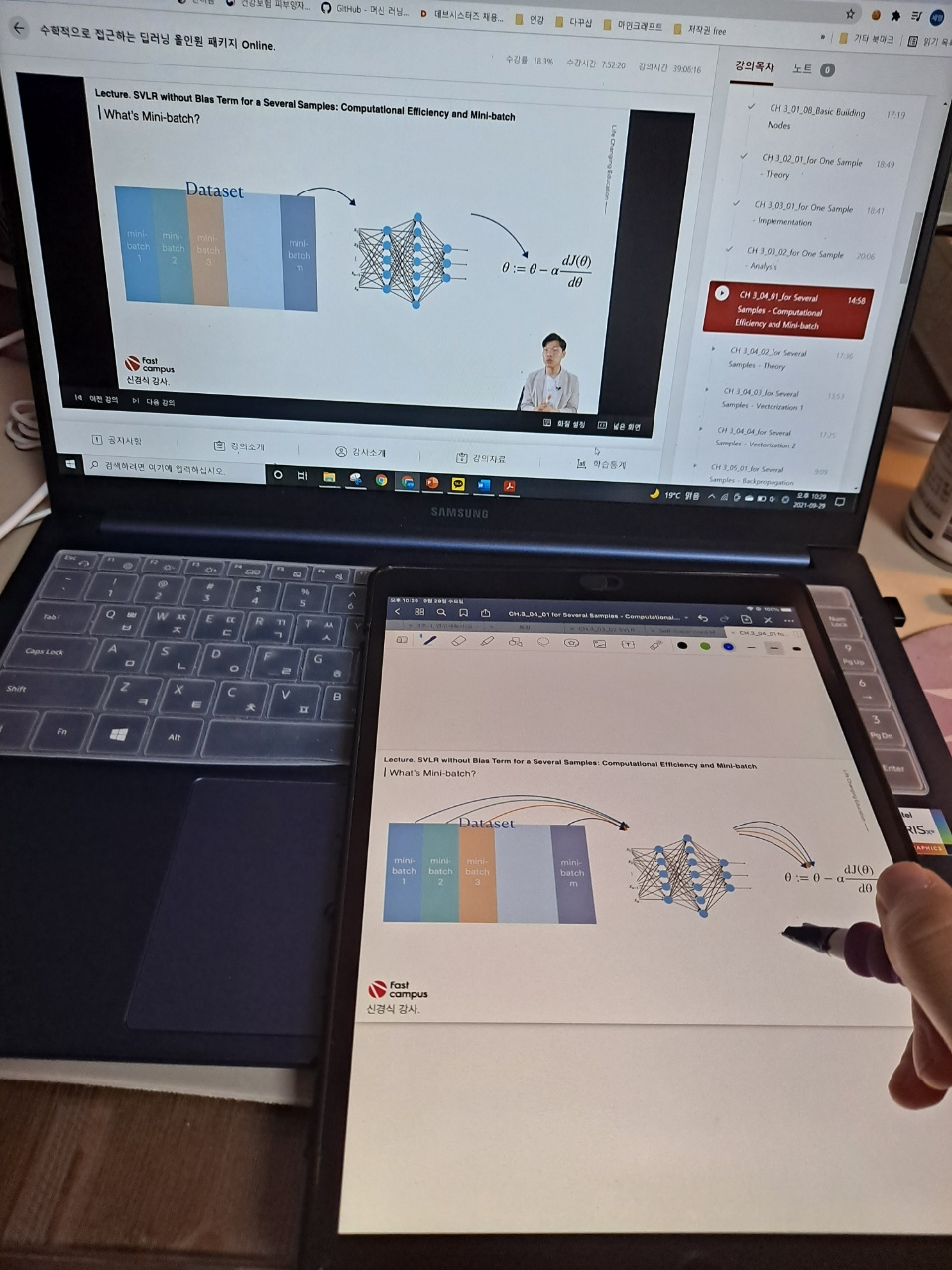
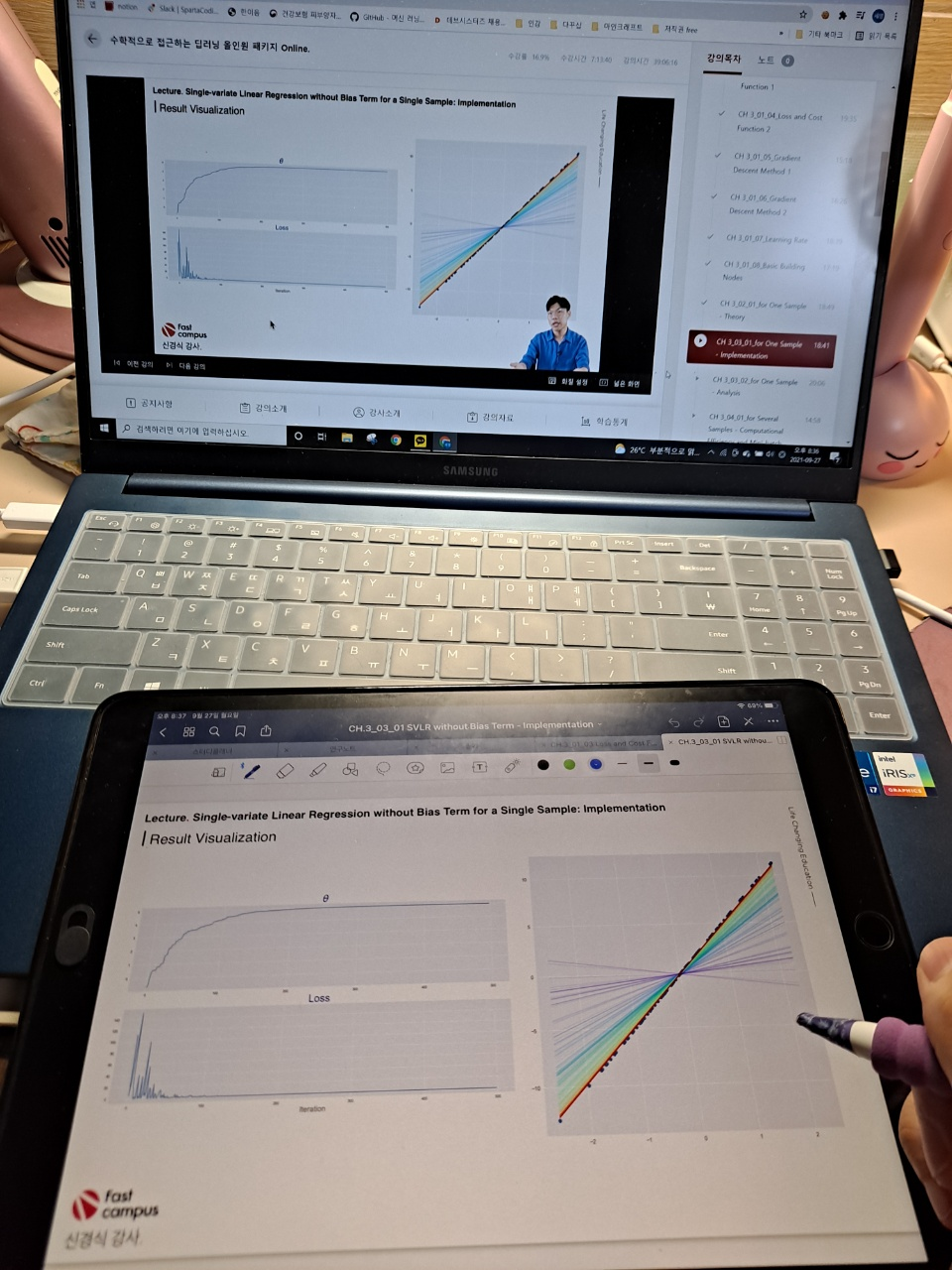
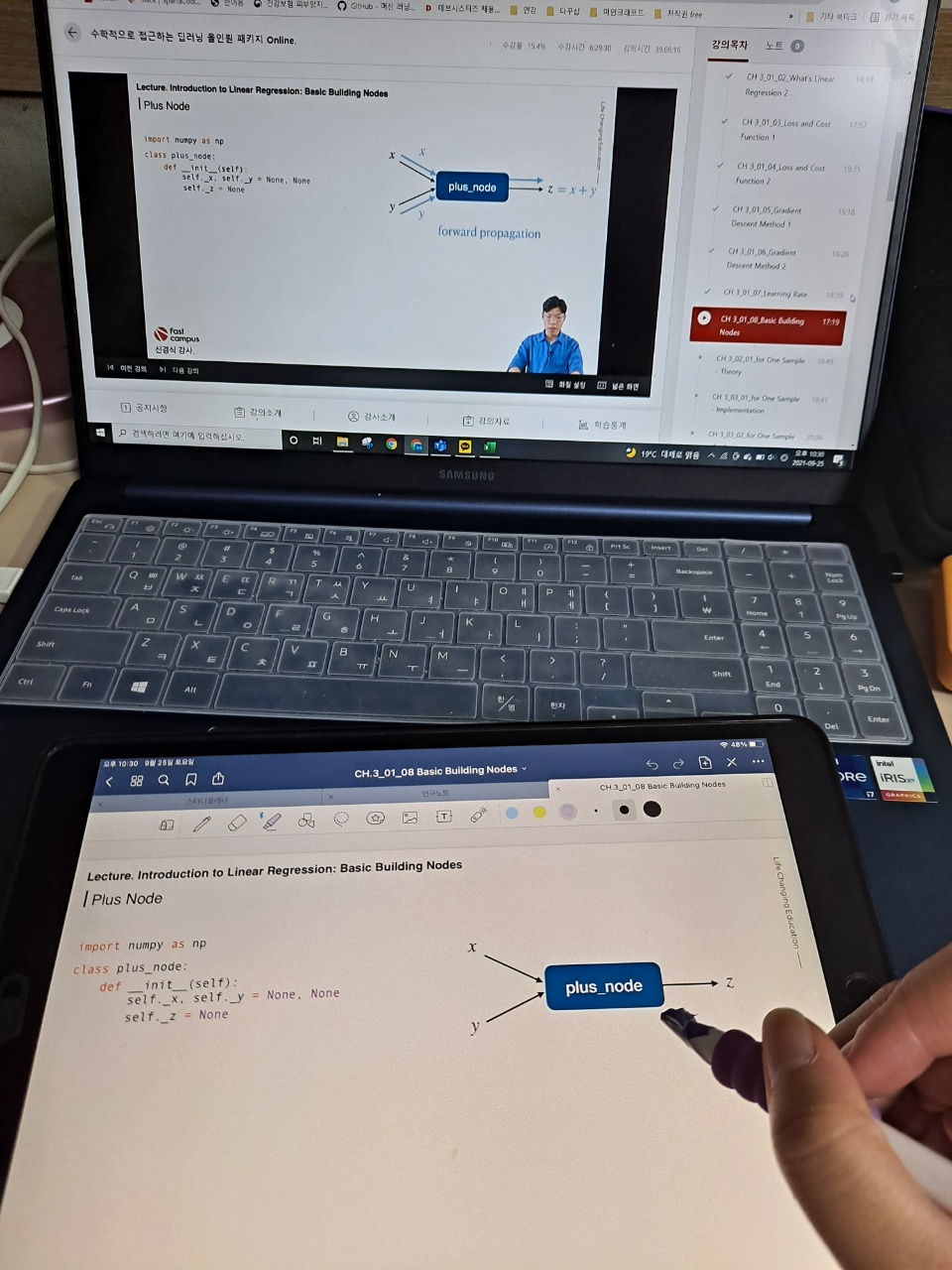
오늘의 강의는 저번 시간에 이어 여러 개의 학습에 대해 배웠다. for Several Samples - theory 라는 강의 제목에서도 알 수 있듯이 여러 개의 샘플을 학습하는 방법의 이론에 대해서 배웠다. 이번 강의에 수식이 많이나오지만 그래도 지금까지 들은 강의가 있어서 맷집(?) 면역(?)이 생긴건지 그렇게 어려워보이지는 않았다.
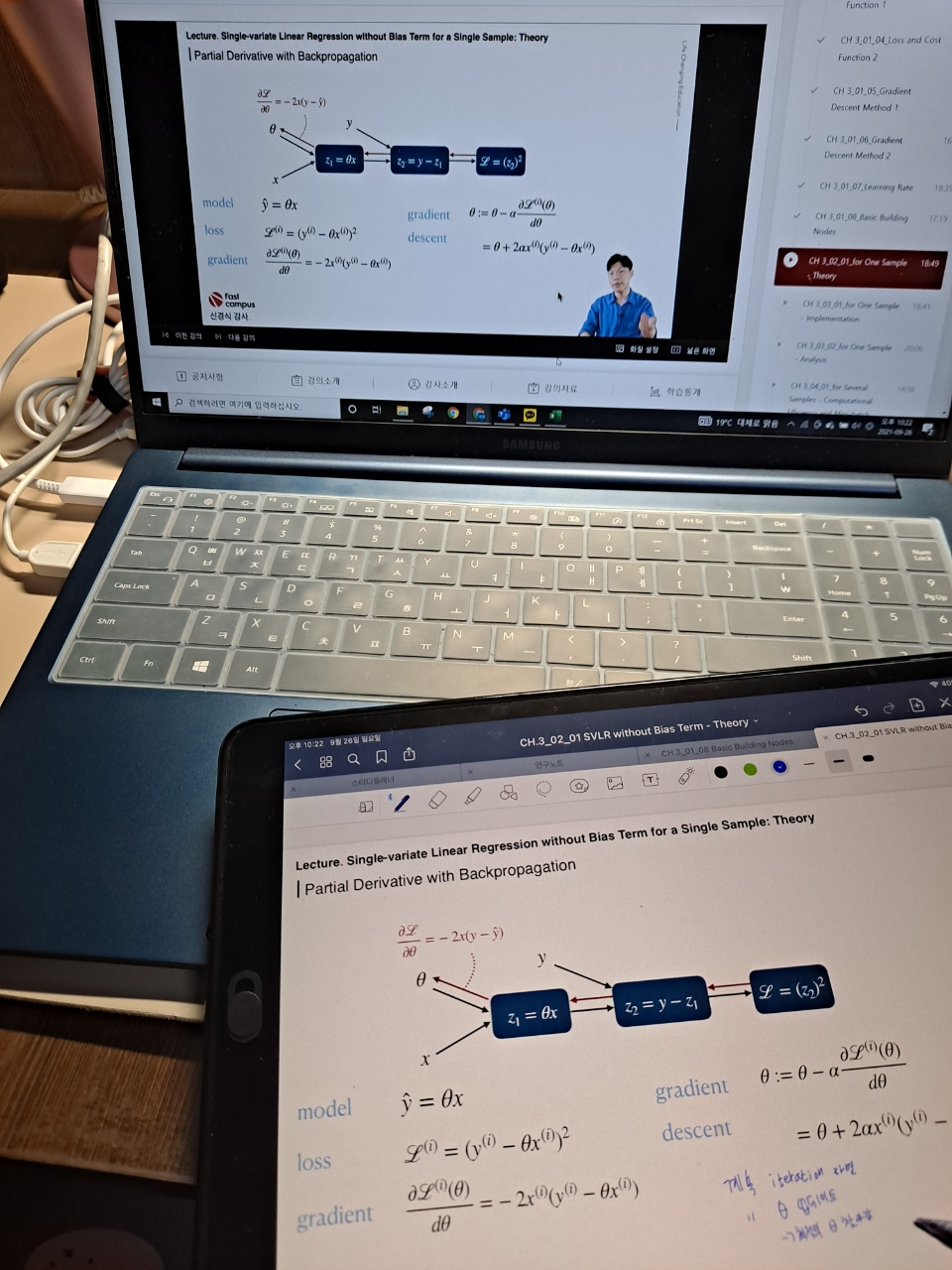
이번 수업의 내용은 모델의 loss와 cost를 구하는데, 여러 개의 샘플에 대해 구하는 것을 직접 하나하나 알려주시는 수업이었다. 수업자료 준비도 힘드셨을텐데.. 수식 입력이 진짜 귀찮기도 하고 시간이 오래 걸리는 작업인데 이 많은 수식을 이렇게 다 하나하나 유도해주셔서 정말 감사하게 들었다. 중복되는 내용이 많긴했지만, 여러 개라고 하니 또 어렵게 보이는 부분이 있기도 했다. 오늘의 수업도 100% 이해한 것은 아니지만 한 67%랄까.. 애매하게 이해했지만 그래도 어디가서 유도과정을 한 번 해봤다고는 할 수 있을 정도인 것 같다.
강의 마지막 즈음에 강사님께서 대중교통으로 이동하는 시간에 다시 한 번 생각해보며 득도할 때까지 한 번 생각을 해보라고 하셨는데, 이 수식을 기억하면서 가는 것도 대단한데 머릿 속에 섬광이 번뜩일 때가 있다는 것도 신기하다..
오늘 랩미팅에서 교수님도 심심할 때 보면 좋을 것 같다고 수식 유도 과정 유튜브 영상 링크를 주셨는데 정말 천재들의 세계란.. 너무 넘사벽인 것 같다.
▼패캠 강의 리스트▼
*본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.*
#패스트캠퍼스, #패캠챌린지 #직장인인강 #직장인자기계발 #패스트캠퍼스후기 #수학적으로_접근하는_딥러닝_올인원_패키지_Online #대학원생공부 #인공지능독학 #머신러닝 #딥러닝
'인공지능 > 수학' 카테고리의 다른 글
| [패캠환급반] 딥러닝 인강 100% 환급 패스트캠퍼스 챌린지 27일차 (0) | 2021.10.02 |
|---|---|
| [패캠환급반] 딥러닝 인강 100% 환급 패스트캠퍼스 챌린지 26일차 (0) | 2021.10.01 |
| [패캠환급반] 딥러닝 인강 100% 환급 패스트캠퍼스 챌린지 24일차 (0) | 2021.09.29 |
| [패캠환급반] 딥러닝 인강 100% 환급 패스트캠퍼스 챌린지 23일차 (0) | 2021.09.28 |
| [패캠환급반] 딥러닝 인강 100% 환급 패스트캠퍼스 챌린지 22일차 (0) | 2021.09.27 |