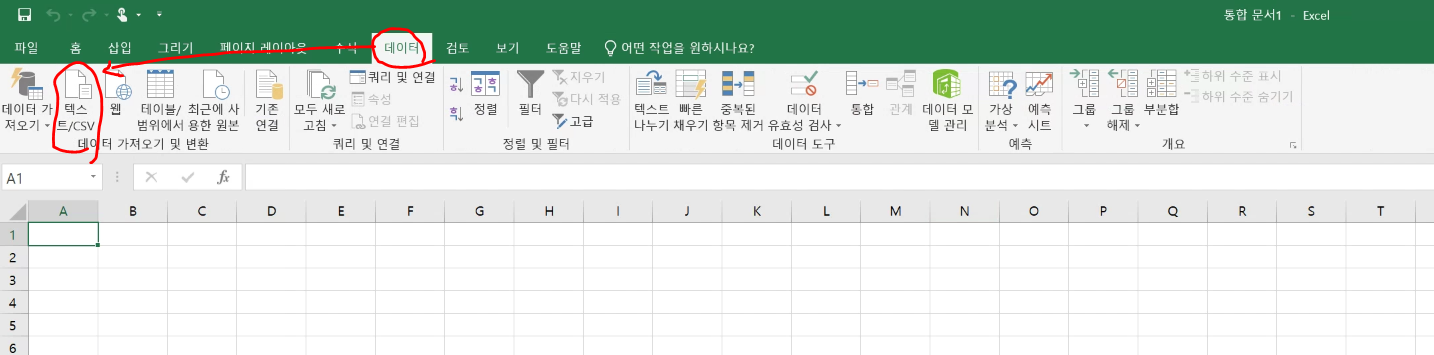
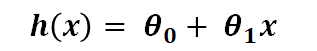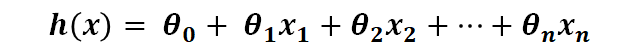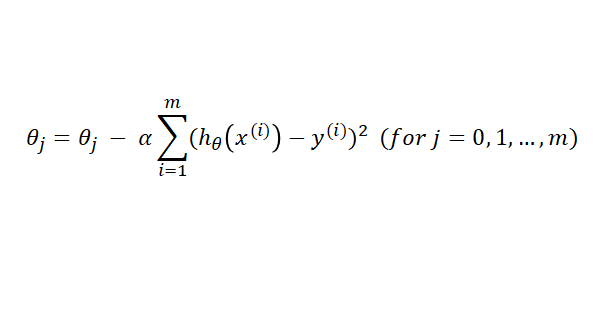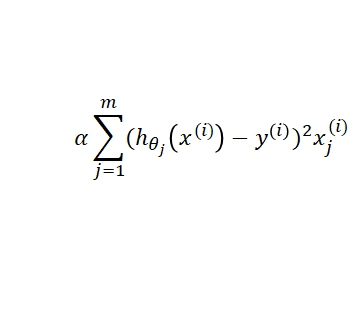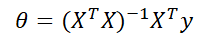패스트캠퍼스에서 100% 환급 챌린지라는 좋은 기회가 있어서 챌린지에 신청했다.
평소에 관심있게 봐오던 강의가 한 5개는 있었는데, 그 중에 제일 듣고 싶고, 가장 비쌌던 수학+딥러닝 강의를 수강했다.
오늘이 바로 1일차! 두근두근하며 강의를 시청했다.
첫 강의는 쉽게 introduction 이었다.
요즘에는 딥러닝 구현을 쉽게 할 수 있도록 Tool이 많이 나오지만, 수학적인 접근이 필요한 이유를 설명해주셨다.
나도 '수학이 필요없는 딥러닝' 혹은 '수학없이 딥러닝 구현하기!' '0일 만에 딥러닝 구현' 이런 식의 책이나 강의를강많이 봐왔기 때문에 이 수업을 수강하기 전까지도 고민이 되었던 부분이었다.
강사님은 이 부분에 대해서 딥러닝 구현은 Tool이 해주기 때문에 쉬워진 것은 사실이지만, 설계에 대한 부분이 미흡하고, 딥러닝의 원리에 대한 이해가 부족하기 때문에 딥러닝의 결과를 해석하기 어려운 것이라고 설명해주셨다.
나도 요즘 explain model 에 대해 관심이 생겨서 이 부분이 잘 이해가 됐다. explain model 논문을 읽고 발표했다가 explain이 되는 원리도 이해를 못해서 교수님께 질문 폭탄을 받고 깨달았다.. 나 수학과 이해력이 많이 부족하구나..
딥러닝의 결과를 A to Z까지 설명하긴 어려울지 몰라도 수학적으로 접근한다면, 어느 정도는 해석할 수 있을 거라고 하셨다. 내 다음 연구에서 활용하기를 정말 고대해본다..
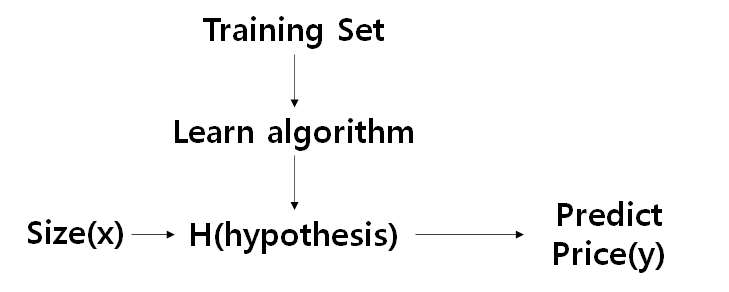
그리고 딥러닝에 대해서 설명해주셨다.
딥러닝을 공부하는 사람이라면 정말 기초적인 Multi Layer Perceptron(MLP) 구조부터 설명해주셨다.
그런데, 이 구조를 알고는 있었지만, 이해하지 못 하고 있었다는 것을 바로 느꼈다.
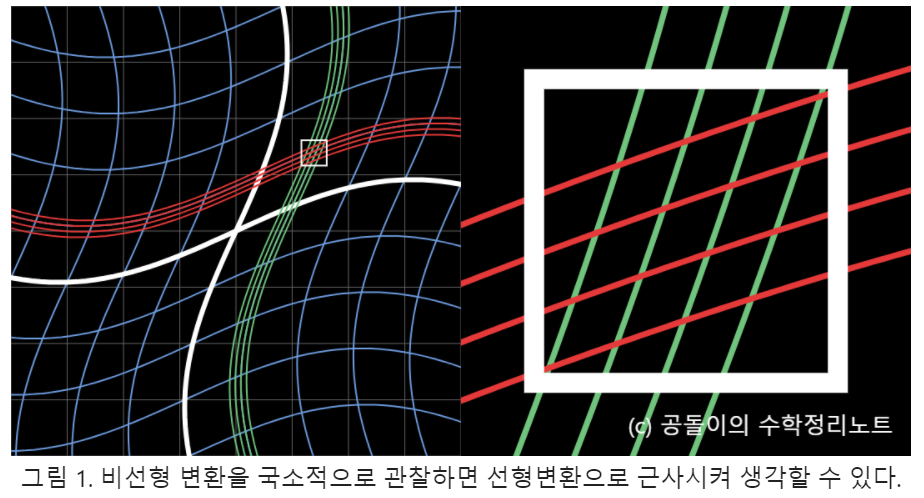
MLP, CNN, RNN 구조를 비교해주셨는데, 결국 세 네트워크 모두 Weighted sum을 계산하고, 그 값을 activation function 으로 연산해서 값을 넘겼다.
이 연산은 달라지지 않았다.
새로운 네트워크를 배울 때마다 너무 어려웠는데, 이렇게 원리를 알고 보니 새삼 쉽게 느껴졌다.
오늘은 소개만 해주셨는데, 앞으로 이러한 연산에 대해서 깊게 배울 거라 생각하니 기대되었다.
이 강의는 딥러닝을 막 시작한 입문자에게는 어려울 것이다.
전문용어(라고 말하지만 그냥 영어)를 많이 말씀하시고, MLP, CNN, RNN의 기본 구조를 몰랐었다면 아마 introduction 강의도 알아듣기 어려웠을 것이다. 물론 그 구조를 설명하시는게 아니라, 예를 들어주신 것이었지만, 아무것도 모르는 상태라면 어려웠을 것이다.
오늘이 OT라서 그렇게 느꼈을지 모르니 앞으로 계속 들어가며 난이도를 파악해봐야겠다.
▼패캠 강의 리스트▼
https://bit.ly/37BpXiC
*본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.*
#패스트캠퍼스, #패캠챌린지 #직장인인강 #직장인자기계발 #패스트캠퍼스후기 #수학적으로_접근하는_딥러닝_올인원_패키지_Online #대학원생공부 #인공지능공부 #인공지능독학 #딥러닝
'인공지능 > 수학' 카테고리의 다른 글
| [패캠환급반] 딥러닝 인강 100% 환급 패스트캠퍼스 챌린지 5일차 (0) | 2021.09.10 |
|---|---|
| [패캠환급반] 딥러닝 인강 100% 환급 패스트캠퍼스 챌린지 4일차 (0) | 2021.09.09 |
| [패캠환급반] 딥러닝 인강 100% 환급 패스트캠퍼스 챌린지 3일차 (0) | 2021.09.08 |
| [패캠환급반] 딥러닝 인강 100% 환급 패스트캠퍼스 챌린지 2일차 (0) | 2021.09.07 |
| [패캠환급반] 패스트캠퍼스 인공지능 수학 강의 30일 환급 챌린지 도전! (0) | 2021.08.31 |