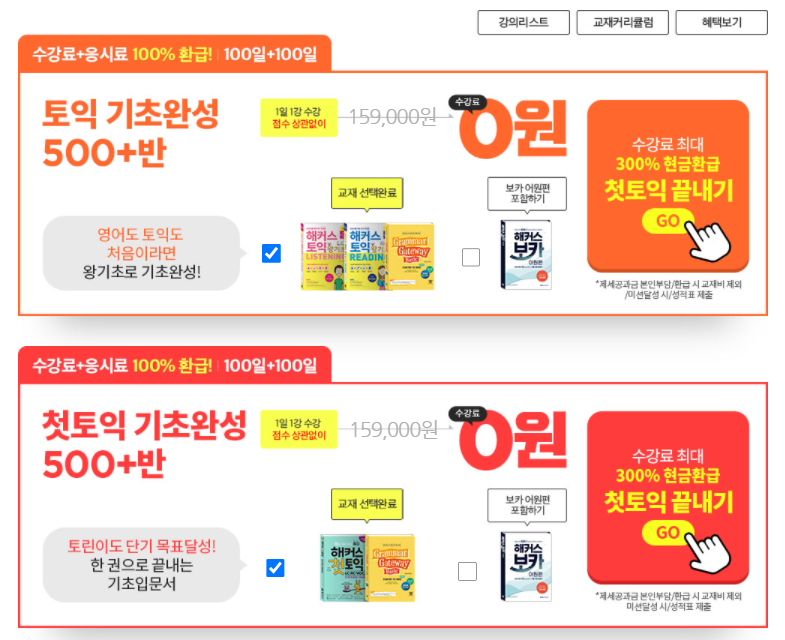
강의를 듣는 것은 자유이긴하지만, 기본 지식으로 행렬의 곱, 벡터의 연산 등 기초적인 수학 지식이 있어야한다.
이진트리, 스택 등의 기초적인 컴퓨터 공학 지식도 필요하다.
만약 이러한 컴퓨터공학분야의 지식이 부족하다면 그 부분을 먼저 공부한 뒤 이 강의를 듣는 것이 좀 더 수월할 것이다.
아직 본 강의를 많이 수강하지 않아서 난이도는 잘 모르겠지만, 수학적 지식이 부족하여 망설여진다면 Coursera의 Machine Learning - Andrew Ng 강의를 듣는 것도 나쁘지 않을 것이다. 이 강의는 스터디를 한 번 했었는데, 수학에서 모르는 개념을 알려주어서 수강하기에 괜찮았다. 다만, 수학을 너무 쉽게쉽게 설명하고 넘기셔서 어렵게 느껴지는 부분이 있기도 했다. 하지만 한 번 훑기에 좋은 강의같다.
프로젝트
이 수업은 스탠포드 대학교의 강의이므로 과제가 있다. 물론 유튜브로 청강하는 사람들은 과제를 할 필요는 없지만, 스탠포드 학생들의 프로젝트 결과물을 볼 수 있다.
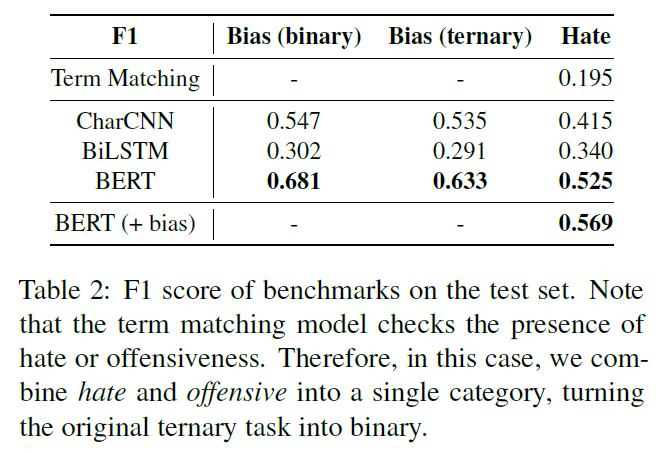
수동적으로 labeld 된 hate speech dataset 이 있는 영어, 독일어, 이태리어에서는 Hate speech detection 연구가 진행되었다. 본 연구에서는, 우리는 처음으로 9.4k의 연예뉴스 댓글에서 모아진 Korean toxic speech data 를 제공한다. 이 데이터셋으로 charCNN, BiLSTM, BERT 모델을 기준으로 성능을 측정해보았다.
1. Introduction
한국에서 악성댓글로 인해 자살한 어린 두 명의 연예인이 있었다. 이 사건으로 한국 인터넷 기업 2곳이 댓글 시스템을 모집했고, 지금은 악성댓글을 피할 수 있지만, 근본적인 문제는 아직 풀지 못했다. 우리는 이 social issue 에 대처하기 위해 toxic speech detection 을 위한 최초의 Korean corpus 를 제안한다. 이 데이터셋은 social bias와 hate speech 두 가지 측면에서 annotation 을 진행했다.
다음은 본 연구의 주요 기여점(contribution)이다.
처음으로 hate, bias(편견)에 대한 Korean corpus를 구축하고 배포하였다.
향후 개발을 위해 Kaggle Competition 을 개최하였다.
bias(편견)이 hate speech detection 에 도움이 되는 것을 관찰하였다.
2. Related Work
한국어에서 abusive language (비속어, 악성댓글 등)관련 연구는 '용어'(term)의 질적 논의에 초점을 맞춰왔다.
term matching 접근법은 신조어, 다의어 등으로 예측에 한계가 있다. 더 중요한 것은, 모든 hate speech가 비속어를 사용하지는 않는다. 또한, 혐오 표현은 사회적 편견, 맥락 안에 위치한다. 이전연구에서는 주로 성차별적, 인종차별적 용어를 명시적으로 보여주는 텍스트에 관심을 보였다.
본 논문에서는 명시적, 암시적 고정관념을 고려하고 이러한 고정관념이 혐오 발언과 어떻게 관련이 있는지를 면밀히 조사한다.
3. Collection
연예 뉴스에서 수집한 comments data 로 Korean Hate Speech corpus 를 구축하였다.
2018. 1. 1 ~ 2020. 2. 24 까지의 23,700 개의 기사에서 10,403,368 개의 댓글을 수집하였다.
그 중 복제된 댓글, 한 단어 댓글(모호한 것 제거를 위해), 100자 이상 댓글(너무 여러 의견을 전하므로)을 제거하였다.
마지막으로 10k의 댓글이 무작위로 선정되었다.
Figure 1
figure 1은 comment 샘플이다. 샘플은 6개의 parts로 구성되어있다.
1. 작성일자
2. 시간
3. maked ID (비식별화된 ID)
4. 내용
5. 답글 수
6. 좋아요/싫어요 수
상기 10k댓글과 관련하여 모든 기사에 대해 동일한 점수로 정렬된 상위 100개의 댓글을 모아 2M개의 댓글을 준비하였다. 이 추가 corpus 는 label 없이 배포된다.
4. Annotation
32명의 annotator 들이 annotation 을 수행해주었다. 모든 댓글은 다수결 판단을 위해 무작위로 3명에게 주어졌다. annotators 는 각 코멘트마다 2개의 3선지 질문에 답했다.
어떤 종류의 bias(고정관념, 편견)이 있나요? ①성차별 ②다른 bias들 ③없음
다음 카테고리 중 해당 댓글에 가장 적절한 카테고리는 무엇인가요? ①Hate ②Offensive ③없음
너무 모호할 경우 skip할 수 있었다. 세부적인 지시사항은 appendix.A에 있다.
4.1 Social Bias
social bias 란 특정 사회적 특성을 가진 개인/집단으로의 편견이다 (성, 지역, 외모, 나이, 장애, 인종 등등)
우리의 주요 관심사는 성차별(gender-bias)이지만, 다른 이슈들도 과소평가되지는 않았다.
따라서, 우리는 label을 3개로 나누었다. gender bias / other bias / None
gender bias / none 의 binary version 도 공개한다.
label 에 대한 annotator 간의 합의는 크리펜도르프 알파(Krippendorff's alpha)를 기반으로 계산한다.
세 개 클래스의 IAA(inter-annotator agreement)는 0.492로 합의가 원만한 정도였다.
특히 binary case 에서의 IAA 는 0.767로 상당한 합의에 도달한다.
4.2 Hate Speech
한국어에서는 악플에 대한 정의가 부족해서 유튜브, 페북, 트위터의 악성댓글 관련 정책을 참고했다. 우리가 정의한 hate speech 코멘트의 정의는 다음과 같다
성, 나이, 외모, 지역, 질병 등에 대한 혐오가 노골적으로 드러나있을 때
sexual harassment, humiliation, 그리고 derogation 을 포함하는 개인/집단을 심하게 모욕하거나 공격할 때
모든 악성댓글이 위 조항에 속하지는 않는다. 이보다 덜한 수준의 댓글은 offensive라고 정의하고 다음과 같은 기준을 가진다.
댓글이 의문문이나 반어법을 통해 빈정거릴 때
댓글이 비도덕적이고 무례한 의견을 가진 상태일 때
표현의 자유로서 댓글이 암시적으로 특정 개인이나 집단에 공격을 하고 있을 때
5. Corpus
10k의 corpus 중 합의가 안 맞는 659개는 폐기처분 했다. 최종 dataset 을 train(7,896), validation(471), test(974) 로 나누었다. testset의 label은 공개되지 않는다.
hate speech의 존재는 social bias의 존재와 관련있다고 확신한다.
다시말해서, social bias를 포함한 댓글이면 hate나 offensiv speech 일 가능성이 있다.
6. Benchmark Experiment
6.1 Models
본 연구에서는 3개의 baseline 분류기를 구현했다. (CharCNN, BiLSTM, BERT) BERT는 koBERT를 사용하였다.
그리고, koBERT의 Tokenizer 를 BiLSTM에 적용하였다. 각 모델에 대한 자세한 configuration은 Appendix.B 에 있다. 그리고 상술한 단어 기반 접근법(term-matching approach)와 비교해봤다.
6.2 Results
위 Table 2에서 보듯이 BERT가 최고 성능을 보여주었다. 각 모델은 각기 다른 성능과 다른 특성을 보여주었다.
Bias detection
gender-bias detection 은 CharCNN의 성능이 좋았다. 왜냐하면 CharCNN은 어휘적인 요소(he, she, man, woman, ...)를 잘 포착하기 때문이었다. 그러나, 그러한 특성 때문에 CharCNN은 false prediction을 유발하는 특정 용어에 지나치게 영향을 받는다.
예를 들어
"What a long life for a GAY" 이 문장에서는 bias 를 탐지하지 못했지만
"I think she is the prettiest among all the celebs" 이 문장에서는 'she'의 사용으로 bias 를 포함하고 있다고 예측했다.
CharCNN 은 3개 클래스 분류에서도 BiLSTM보다 성능이 좋았다.
BERT는 두 분류 모두에서 성능이 뛰어났따. BERT의 풍부한 어학 지식과 문맥정보가 bias 인지에 도움이되는 것을 알 수 있었다.
세 모델 모두 other bias 에서는 성능을 잘 내지 못했다. 더 좋은 시스템 구성을 위해 label을 non-gender bias로 예측하는 것이 나을 것이다.
ex) 1 - bias or not, 2 - gender bias or not
Hate speech detection
hate speech detection 에서는 세 모델 모두 bias 탐지보다 성능이 낮았다. 왜냐하면 hate speech detection 이 보다 어려운 Task 이기 때문이다. 그럼에도 불구하고 BERT는 좋은 성능을 보였다.
hate speech detection 은 의미적 특징도 활용한다고 추측한다. BERT와 term matching 접근법은 false prediction에 대해 얼마나 보상하는지를 성능차이가 설명해준다.
7. Conclusions
본 논문에서 우리는 9.4k의 Korean toxic comments corpus 를 구성했다. 우리의 데이터셋은 toxic speech에 대한 연구를 촉진하고 사이버 불링 문제를 개선하는데 도움이 될 것이다.
ISO 690
Moon, J., Cho, W. I., & Lee, J. (2020). BEEP! Korean Corpus of Online News Comments for Toxic Speech Detection.arXiv preprint arXiv:2005.12503.
파이썬 프로그래밍을 하다보면 버전이 맞지 않아 업데이트된 버전을 다시 다운로드하기도 하고, 다운그레이드 버전을 설치하기도 한다.
그러면 파이썬 버전이 충돌해서 오류가 생기는 경우도 있다.
그럴 때 사용하는 것이 아나콘다!
아나콘다에서는 여러 개의 가상환경을 생성해서 가상환경별로 실험 환경을 관리할 수 있게 한다.
만약 여러 개의 파이썬 버전을 사용한다거나, 여러 프로젝트를 동시에 진행하고 있을 때 각 프로젝트마다 가상환경을 만들어 사용할 수 있을 것이다.
또한, 파이썬 버전 충돌이나 어떠한 오류가 발생했을 때 컴퓨터를 포맷할 필요 없이 가상환경을 지우고 다시 생성해서 설치하면 되므로 오류발생 시 좀 더 편리한 환경을 제공한다.
필자는 파이썬 버전 충돌 오류를 너무 많이 만나서 아나콘다를 설치하려고 한다. (최근에는 Google Colab 을 더 많이 사용하다가, 프로젝트 진행으로 새로 환경을 구축하려 한다.)
또, 파이썬 모듈 설치시 pip 명령어로 설치해야하는 것들이 있는데, 이 경우에도 conda 명령어로 설치할 수 있다.
큰 차이는 모르겠지만 conda 명령어로 가상환경에 모듈을 설치하면 좀 더 간편한 느낌이 들었다.
Anaconda 설치하기
Google 검색창에 Anaconda 를 검색하면 가장 첫번째로 anaconda 홈페이지가 뜬다.
클릭해서 들어가자.
홈페이지에 들어가면 편리하게도 바로 Get Started 버튼이 뜬다. 클릭해서 다운로드하자.
클릭하면 위와 같이 행복한 미소의 모델분께서 여러 선택지를 제시해주신다. Download Anaconda installers 를 클릭해서 다운로드 받자.
위와 같이 자신의 운영환경에 맞게 Installer 를 다운 받을 수 있다. 필자는 윈도우즈 환경이므로 Windows 에서 64비트 인스톨러를 다운받을 것이다.
클릭해서 다운로드 받으면 위와 같이 뭔가 클릭해야할 것 같은 Buy Now 버튼이 뜨는데 절대 클릭하면 안된다! 다운로드는 끝난 것이다. 인스톨러는 다운로드 되었으므로 웹페이지 하단을 확인하거나, 다운로드 폴더를 확인해보자.
필자는 웹페이지 하단을 확인해보니 다운로드가 다 되어있었다. 이 exe 파일을 실행해서 설치하자.
인스톨러를 실행시켰다. Next 를 눌러 다음으로 진행한다.
(여담이지만, 2020. 11 버전이라니 아나콘다 업데이트 언제 되나 했는데 꽤 최근에 한 번 됐나보다.)
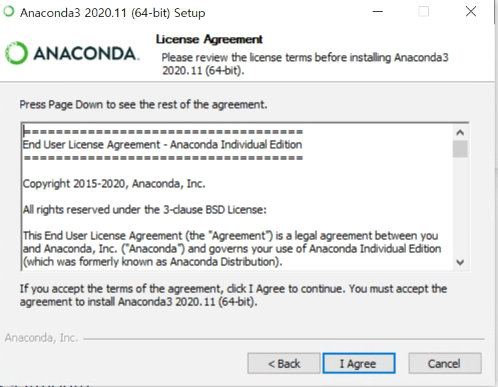
아나콘다 이용 약관에 동의하겠냐는 화면이다. 동의하지 않으면 넘어갈 수 없으니 I Agree 버튼을 클릭해서 다음 단계를 진행하자.
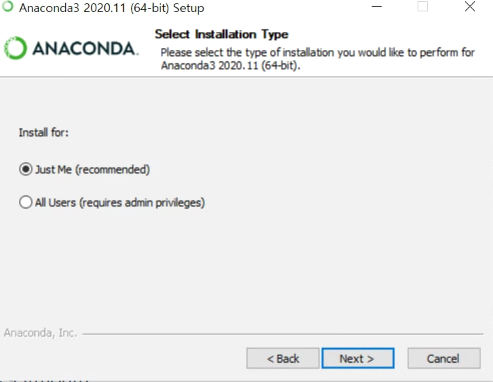
설치 타입을 묻는 창이다. 개인용이면 Just Me 옵션을 선택하고 Next 를 클릭하면 된다.
All Users 옵션은 잘 모르겠지만, admin 권한을 필요료한다는 것을 봐서는 리눅스환경과 같이 다중 사용자를 위한 옵션인 것 같다.
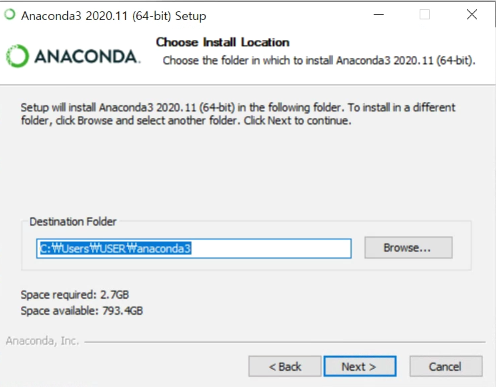
아나콘다의 설치 경로를 설정하는 창이다. 필자는 기본 경로에 설치하려하므로 그냥 Next 를 눌러 다음 단계로 진행한다. 혹시 경로를 변경하고 싶다면 Browse... 을 클릭해 원하는 경로에 설치할 수 있다.
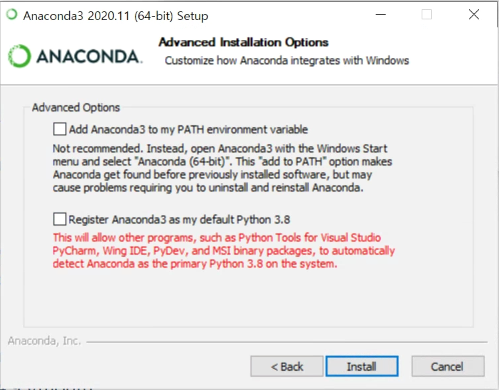
아나콘다 옵션을 설정할 수 있는 창이다. 첫번째는 환경변수에 Anaconda3 를 설정할 것이냐 묻는 것이다. Not recommend 라고 비추한다는 말을 강조해놓기도 했고, 필요하면 환경변수에 직접 등록할 수 있으니 패스했다.
그리고 두 번째는 Anaconda3 에 기본 Python 버전을 3.8로 설정하겠냐고 묻는 것이다. 체크가 기본으로 되어있고, 해제하니 저렇게 붉은 글씨로 되었다. 필자는 굳이 3.8로 설정해놓을 필요가 없기도 하고, 3.6을 기본으로 생각하고 있어 일단은 해제해주었다.
옵션 설정이 끝났다면 Install 로 설치를 진행하자.
이후의 창들은 모두 Next 를 눌러 넘어가 주면 이렇게 마지막 창이 뜬다. 두 개의 체크 박스 중에 첫번째는 튜토리얼 에디션인 것 같다. 귀찮으니 체크를 해제해주고, 두번째 박스인 아나콘다 바로 실행만 체크해주고 Finish 버튼을 눌러 실행해보자.
Anaconda 를 실행해주는 줄 알았는데, 홈페이지의 교육을 실행해준다는 말이었나보다.
아나콘다에 가입하고, 튜토리얼 영상을 보고 싶다면 위의 양식을 작성해서 로봇이 아님을 증명하고 Reister 를 하면된다.
필자는 창을 닫고 시작메뉴에서 아나콘다를 실행해주었다.
아나콘다 설치완료! 이제 실행해보자!
이렇게 시작메뉴에서 ana만 쳐도 아나콘다가 뜬다. Anaconda Prompt 는 CMD 창처럼 CLI 방식으로 동작하는 프롬프트창이다. 가상환경이 급하다면 프롬프트창에서 바로 새 가상환경을 activate 하는 방법을 찾으러가면 된다.
블로그 포스팅이니 좀 더 Graphical 한 자료를 위해서 Anaconda Navigator 를 실행해보았다.
바탕화면에 이런 그림이 뜨면서 Navigator가 로딩된다.
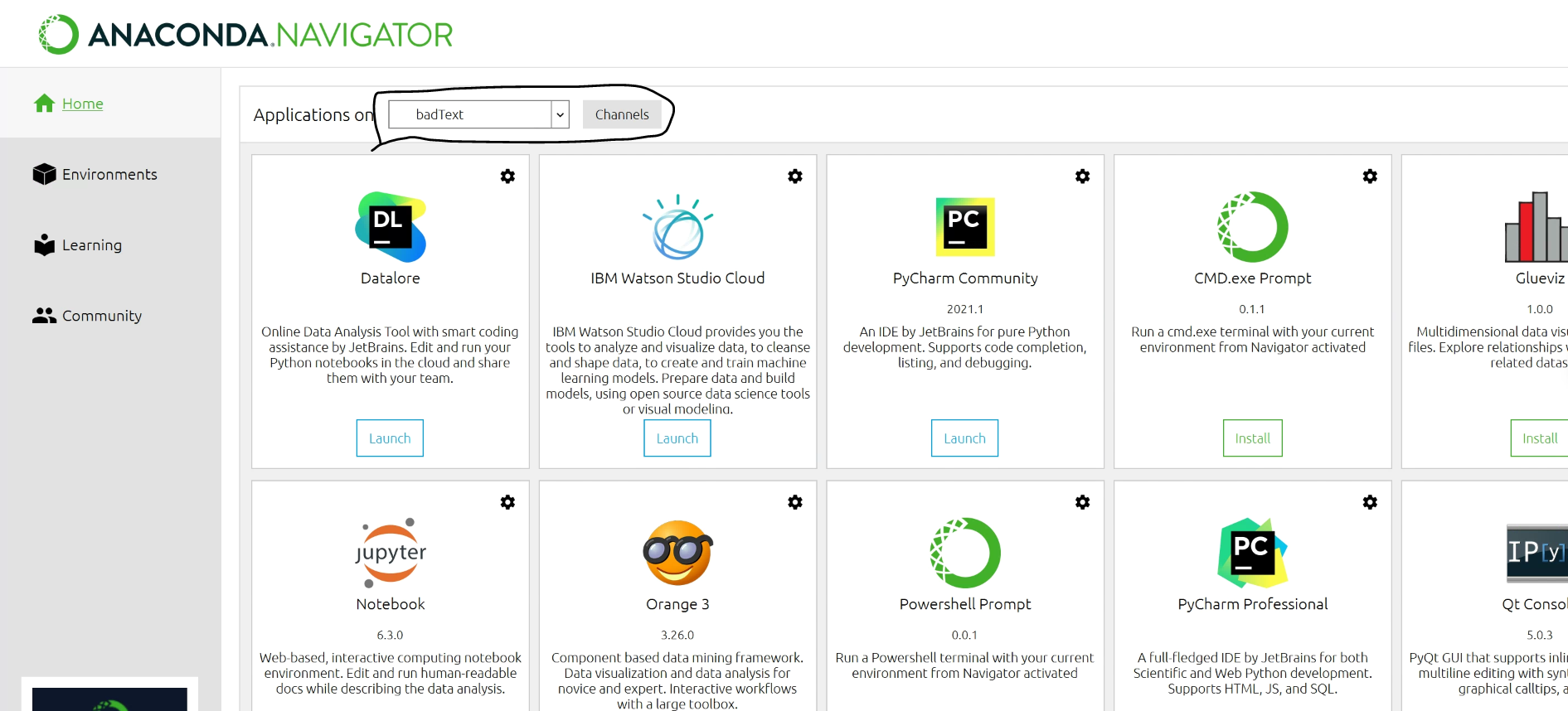
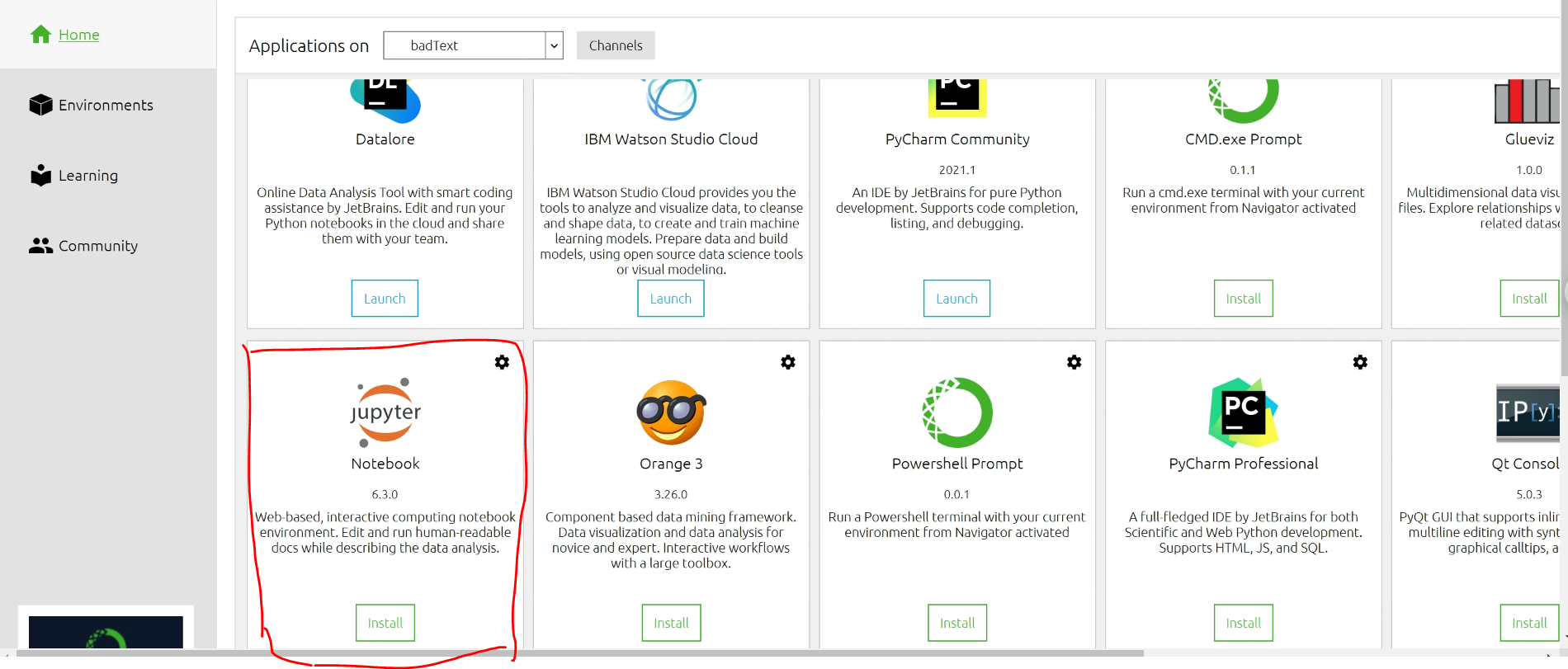
네비게이터의 메인 창이다. 여기서 필요한 툴이 있다면 Launch 버튼을 클릭해서 설치할 수 있다. (예를 들어 Jupyter)
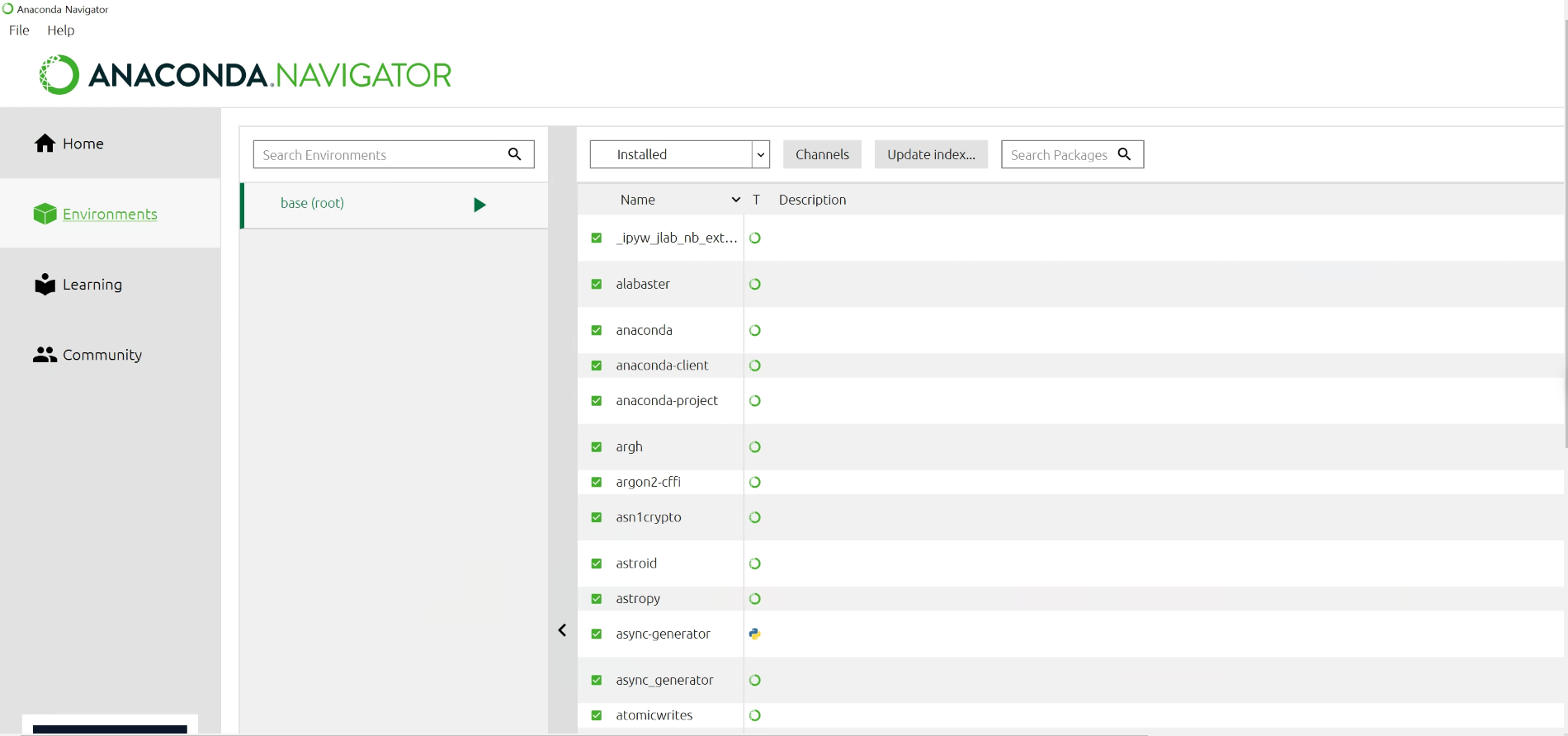
그리고 위에 줄에 Application on 옆에 드롭다운박스(Dropdown box)에 base(root) 가 있는 것을 확인할 수 있는데, 가상환경을 여러 개 만들면 여기에 가상환경목록이 뜬다.
Environments 도 확인해보자.
아직 생성한 가상환경이 없어 base 환경만 확인할 수 있다. 어떤 것이 install 되어있는지를 확인할 수 있다.
오늘은 아나콘다 가상환경 설치를 진행해보았다. 가상환경 생성 및 다른 기능들은 다음 포스팅에서 준비해보겠습니다.